You might think that a machine learning (ML) specialist company like Intellegens is always pursuing the perfect model - one that takes a new set of system inputs and predicts their outputs correctly every time. But, despite the importance of model accuracy, it is possible to focus on it too much in real-world R&D.
A ‘near-perfect’ model – typically considered a model that predicts outputs reliably to within 5% - could mean that machine learning (ML) has found a set of robust relationships not previously observed by cutting through multi-dimensional complexity.

Image Credit: Intellegens Limited
However, this can also mean that experiments were poorly designed or trivial, and the ML is simply confirming the obvious. Such perfection is, in any case, mathematically unachievable in many complex systems with inherent uncertainties.
In the real world of R&D, a typical use case might be designing a set of experiments to find more effective formulations, chemicals, or materials. Here, visualizing the range of possibilities is beyond the capacity of the human brain and even relatively sophisticated Design of Experiments methods still result in large, expensive and time-consuming experimental programs. Users don’t want perfection – they just want ML to shift the odds in their favor, with predictions that outperform the logic currently driving their work.
Pursuing the ideal model may also waste time that is better spent elsewhere. It may also lead to users inadvertently narrowing down their search space in ways that exclude more innovative solutions.
Instead of asking how accurate a model is, the right question may focus on the model’s usefulness. Below are Intellegens’ top five examples of questions that might help a user to shape their model:
1. ‘Can we get to an answer in fewer experiments?’
Does the ML that is being used have the ability to understand what missing data could best improve its accuracy? This information can then be deployed to decide what experiment to perform next, resulting in a significantly reduced time-to-market. In some cases, the Alchemite™ software from Intellegens has reduced experimental workloads by 80%+. More commonly, reductions of 50% are reported.
2. ‘How do we generate new ideas for formulations that achieve our goals?’
New concepts with a chance of success can result from a moderately-accurate model. And R&D teams are given a big helping hand if the model comes with a robust estimate of its uncertainty, pointing them towards those most likely to succeed. If the ML can move the dial so that one in three candidate formulations succeed when the previous metric was one in five, this could make a big difference.
3. ‘Can we remove costly or environmentally harmful ingredients?’
Questions like this typically derive from consumer, regulatory, or market pressure and require a fast response. ML can screen potential solutions, and an indication of probable success can be given by quantifying the uncertainty of the predictions.
4. ‘Where should we focus – which inputs are the most significant?’
The absolute accuracy of predictions may be less important than whether useful relationships are identified, for example, between structure, processing variables, and properties. Often, the latter is the most vital piece of information that users need. A series of analytical tools that enable users to explore the sensitivity of outputs to particular inputs are provided by Alchemite™.
5. ‘Can we make better use of the expertise we’ve already developed?’
Insight developed at great expense in R&D projects is often not be re-used. A valuable starting point for future projects can be provided by the ability to capture this insight in an ML model.
Alchemite™ Analytics – How Do Changes in Inputs Impacts Outputs?
Rather than focusing on ML as a ‘magic bullet,’ it is essential to consider its use in informing scientific intuition and functioning alongside it.
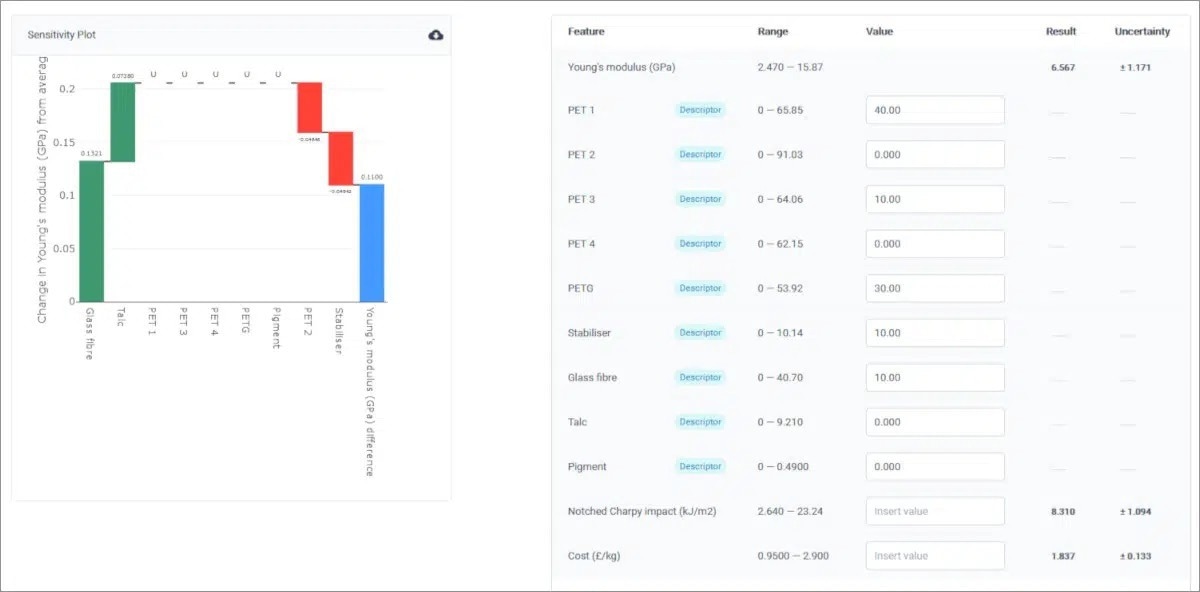
Image Credit: Intellegens Limited
It is vital to have the right tools like uncertainty quantification and graphical analytics to interrogate and understand the results. When data is messy, as it often is in R&D, rather than investing up-front effort to clean and enrich the data, it can be valuable to be able to generate an ML model – even an imperfect one – quickly. By exploring this model, users can gain insight and improve their work iteratively and at a much lower cost.
The team at Intellegens values accurate models, and sometimes, they are, of course, essential. Mostly they also work in the spirit of the aphorism commonly attributed to statistician George Box: “All models are wrong; some are useful.”

This information has been sourced, reviewed and adapted from materials provided by Intellegens Limited.
For more information on this source, please visit Intellegens Limited.